緣起
2007年某日,Dwight Merriman, Eliot Horowitz和Kevin Ryan 成立 10gen 公司。此前他們是 DoubleClick(網路廣告服務商) 的開發團隊,每秒需處理40萬個廣告服務。在嘗試了當時許多 Databases Solutions 時嘗遍了苦頭,找步道一個滿意的解決方案,既然找不到,乾脆自己做。
2009年2月,MongoDB 正式誕生,核心目標是提供簡單高效的資料平台。然而,MongoDB 的路並不順遂。
提起 MongoDB,很多早期的使用者可能都有許多怨言:
- Database/collection-level locking(affecting write performance). That sucks.
- Did not support ACID transaction. That sucks.
- No compression. That sucks.
- Mongodb is not secure. That sucks.
- MongoDB database server is not included in RHEL 8.0 Beta because it uses the Server Side Public License(SSPL) That sucks.
- …

關於 MongoDB有許多迷思與都市傳說,但這些都擋不住小芒果成長的腳步
MongoDB 近年長期保持在DB-Engines Ranking第五名,發展勢頭也是穩步向上
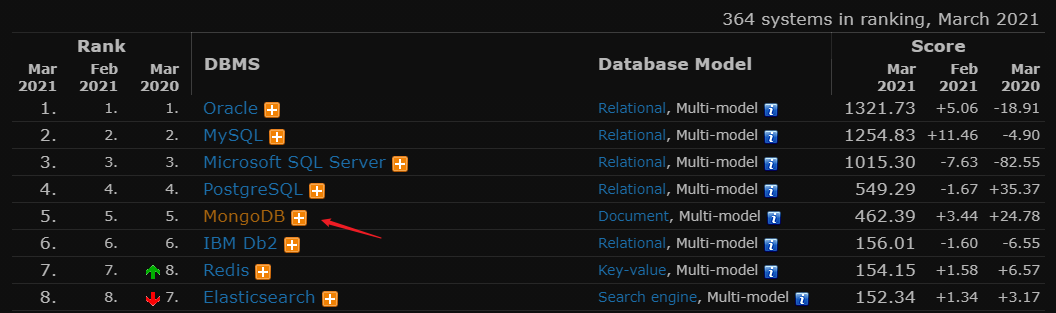
在 Stack Overflow Developer Survey 2020中,不論是在 Most Popular Technologies 還是 Most Loved, Dreaded, and Wanted 的項目中,都可以在前段班看到 MongoDB 的身影。在這些簡單的數據中,其魅力可見一班。
所以說到底,MongoDB 到底是啥?
What’s MongoDB?
MongoDB 由 C++ 所撰寫,是一個基於分散式架構的 document database,生來處理大規模的數據。
MongoDB 的一些重要特性:
- Document-oriented,基於 BSON 的資料結構
- 動態 DDL 能力,沒有強 Schema 約束,支持快速迭代
- 提供記憶體內數據查詢
- 高可用及高擴展特性,可以支援海量資料存儲
- 功能豐富,支持 multi-document transactions、secondary index、change stream 等。
- 跨平台、多語言支持
- 支持 Tunable Consistency
Document-Based
傳統關係型資料庫的資料都是以 column / row 的方式存儲在 table 中,不同種類的資料存在不同的 table,最後再透過 JOIN 的方式聚合資料。在一般的 production 環境,table 之間的關係往往都十分錯綜複雜。而在使用之前,也必須先定義完整可用的 schema,依照自己應用場景的需求設計 ER Model,才能讓應用程式做使用。
而 MongoDB document-base 與傳統關係型資料庫不同之處在於,MongoDB 是將資料以 BSON 的資料型態儲存在 document 中,document 則以 field and value pair 組成。其支援的資料結構也非常豐富,可以是普通的整數、字串、數組,也可以是 embedded documents。embedded documents 的好處在於可以通過一次 query 取得所需的資料,而不需要多表進行 join。

Documents 儲存在 collection 中。每個 document 可以與 collection 中其他的 document 擁有不同的結構或模式,提供了 User 更多的彈性。User 可以根據查詢類型和數據對 document 中的 fields 建立 index,如果想保證所有 documents 都遵循一種資料結構,也可以透過 schema validation 來確保驗證規則。
Document-base 的設計更偏向 denormalized,開發上更符合直覺與彈性。但也不是說 denormalized 或 normalized 誰就一定比誰好,一切都取決於業務面的需求做 tradeoff。Denormalized 除了上面提到的優點,相對於 Normalized 也減少了資料做大量 JOIN 的時間,優化了 Data Read 的效能。但相對的,在資料冗餘或一致性的維護上就比較沒有優勢。但最終如何設計還是需要依照實際應用場景來討論。
總結一下用 Document 儲存資料的優點:
- Document 儲存型態類似於 JSON,在程式開發效率上會有很大提升
- 無須多一層 ORM 在開發框架中
- 查詢效率上高
Comparison With RDBMS
MongoDB 在資料模型的概念上跟傳統的 Relational Database 有許多相似之處,以下是 MongoDB 與 SQL 的術語與概念的對照:
| SQL Terms/Concepts | MongoDB Terms/Concepts |
|---|---|
| database | database |
| table | collection |
| row | document or BSON document |
| column | field |
| index | index |
| table joins | $lookup, embedded documents |
| primary key | _id |
- database: 與 SQL 中 database 概念相同,一個資料庫包含多個 collections(tables)
- collection: 相當於 SQL 中的 Table,一個 collection(table) 中可以儲存多的 documents(rows)。Collection Schema 是動態的,不需事先聲明。默認也不會對寫入的資料做 schema validation
- document: 相當於 SQL 中的 row,一個 row 由多個 fields 組成,並使用 bson 類型
- index: 與 SQL index 相同
- $lookup: MongoDB aggregation operator,實現類似 SQL-Join 的功能
- _id: MongoDB 默認生成 _id filed 來保證 document 的唯一性
High Avaliability
在資料庫世界中,如何維持系統的高可用性是非常重要的一環。MongoDB 提供了 replica set 的解決方案,使用一主多從的架構,利用資料複製的原理組成一組 MongoDB intances 並同時在多個節點儲存資料。利用 replica set 可以實現:
- 資料高可用性,在主機宕機時由 secondary 節點自動投票選舉新的 primary node
- 讀寫分離,讀操作可分流到 secondary 減輕 primary 的負擔
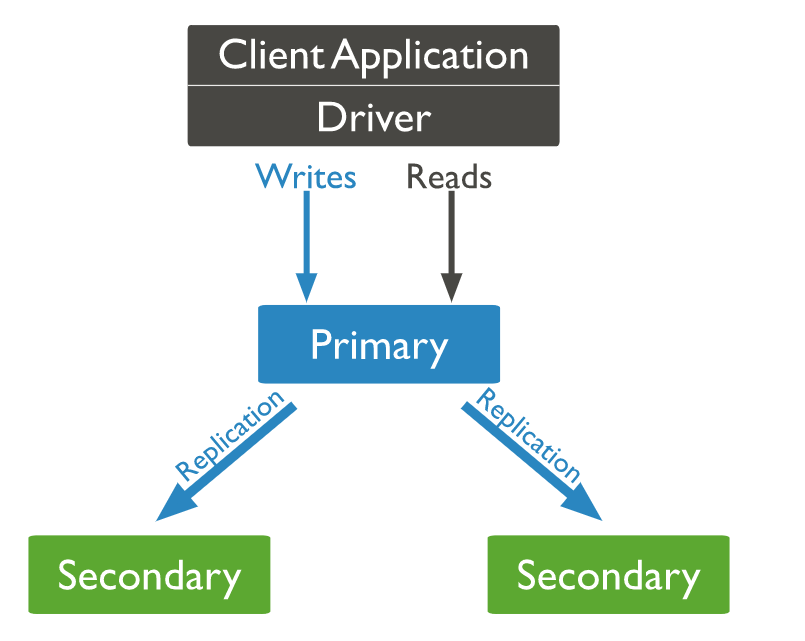
Replica set 組成如下:
- Primary: 主節點負責所有寫操作以維持一致性
- Secondary: 從節點持續從主節點進行資料複製,維護跟主節點相同的資料
- Arbiter: 仲裁節點本身不參與儲存資料,只參與集群選舉
選舉
MongoDB replica set 選舉機制是基於 Raft-Like Consensus 演算法,集群會自動選出滿足所有條件的 primary node 以維持集群正常運作。Primary node 選舉需要滿足多數原則,因此為了避免"平票"的狀況發生,節點數建議以奇數為主,一般採用三節點的方式做佈署。單個 replica set 最多可以佈署50個節點,但具有投票資格的節點僅能存在7個,其餘節點必須作為不可投票節點運行。關於集群節點數與可容錯節點數的比例如下:

Heartbeats
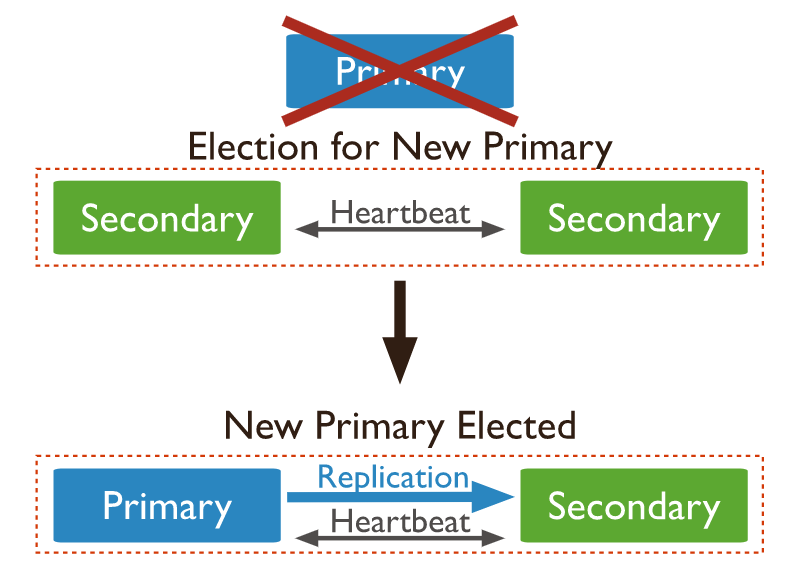
在 replica set 中判斷節點是否宕機就取決於 heartbeats 機制。每2秒鐘集群節點會互相發送 heartbeats 以感知其他節點目前的狀態,如失效或是角色發生改變。利用 heartbeats,MongoDB replica set 實現了自動化 failover。若 secondary 10秒內未收到 primary 的 heartbeat 即觸發選舉機制選出新的 primary,自動完成故障轉移實現高可用性。
High Scalability
MongoDB 使用 sharding 的方式來支撐大數據的存儲及性能的擴展。藉由將資料拆分到多個分片節點上,以解決單機資源難以縱向擴展的問題。與 replica set 不同的是,replica set 是利用複製的方式建立集群,以 data redundancy 的方式提供高可用; 而 sharding 則是將 collections 拆分到不同的 shard 上,並透過 route 的方式來傳送 application operations 到 MongoDB 節點上,以提供高擴展性。
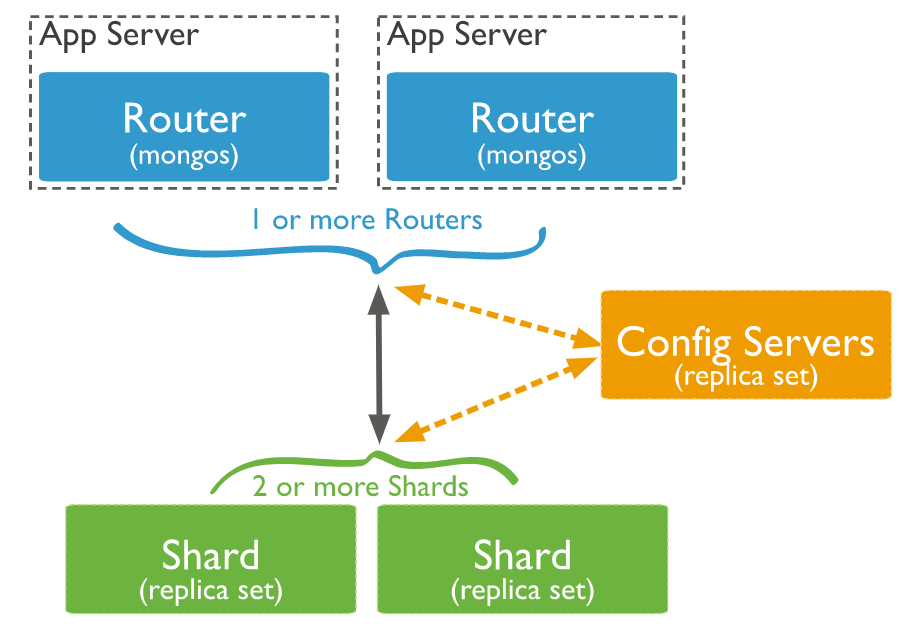
Sharded Cluster 組成如下:
- shard: 每個 shard 存儲一部分分片資料,一般 shard 以 replica set 的方式佈署
- mongos: 相當於集群的入口,擁有 router 的功能,提供 sharded cluster interface,本身不儲存任何資料
- config servers: 負責儲存集群的 metadata 或配置設定
Transaction
在 MongoDB 4.0 版本以前,只支援 single document atomic,透過 embedded documents 或 arrays 的設計來描繪資料之間的關係,這樣就不需要跨多個 documents 或 collections 來操作資料,可以透過單純的 single document atomic 特性滿足一部份的業務場景。
但作為一個定位偏向 OLTP 的資料庫來說,single document atomic 顯然是不夠的,這也是 MongoDB 多年來一直被拿來說嘴的痛點。但從 MongoDB 4.0 版本開始,終於推出了原生的 transaction operation,支援 replica set 中的 multi-document transactions。對於 multi-collection design 的業務場景來說操作上無疑是更加輕鬆方便了。但這仍然不足,依舊無法保證 sharded collections ACID。
隨著 MongoDB 4.2 進一步發布,MongoDB 宣布正式支援 sharded collection multi-document transactions,並向下兼容 replica set multi-document transactions,也終於讓 transaction 的功能更完整。MongoDB 默認的存儲引擎 WiredTiger 使用的是 snapshot isolation level,並採用 MVCC 的策略實現 concurrency。
Consistency
作為以分散式架構為主要發展方向的 database,MongoDB 自然難逃 CAP 理論下的 Consistency problem。CAP 架構中,由於網路分區的存在,系統必須在 consistency 與 availability 之間去做取捨。因此如何在讀寫操作在不同節點上的情況下保證讀取到最新寫入的資料就成為值得思考的問題。
而 MongoDB 採用的是 Tunable Consistency 的概念,將選擇權交給使用者來決定。MongoDB 提供以下幾種 interface:
- Write Concern:關注 data durability,可指定寫入資料需要複製到多少 replica set member 上才能返回成功
- Read Concern:關注 data recency and durability,可指定讀取本地最新資料或已複製到大部分節點的資料
- Read Preference:關注 data availability,可指定資料讀取以 Primary 為主,或以 Sencondary ,或讀取最近節點
使用不同的設定會產生對於 consistency 與 availability 不同的抉擇。以下參考幾個案例對組合的用法:
- Majority reads and writes:將資料安全性放到最高優先級,可以避免因節點故障而導致 data rollback 的情況。假設勞保局的資料更新網站流量不大,大約幾分鐘有一筆寫入。考慮到提交修改資料的勞工無法接受刷新後資料丟失的狀況,就可以通過通過犧牲讀寫性能來保障資料持久性
- Local reads and Majority writes:假設 Facebook 使用 MongoDB,User 絕對無法忍受自己的評論或發文因為主節點當機切換而丟失,但是不會太在意可能因 rollback 而消失的一則評論。兼顧到性能選擇讀取本地節點最新的資料,並確保寫入資料的持久性較為適當
Index
MongoDB 同樣以支持豐富的 Index 總類。可以利用 Index 的使用達到快速查找資料的目的,並根據不同的應用場景設計不同的 Index 方案。MongoDB Index 在底層是以 B+ Tree 實作,與大部分 RDB 相同。這也使得大部分對於 SQL-Like Database 的 index tunning 方式也適用於 MongoDB。
MongoDB 支持的 Index 總類包括:
- Single Field
- Compound Index
- Multikey Index
- Wildcard Index
- Geospatial Index
- Text Indexes
- Hashed Indexes
MongoDB 也提供 explain() command 用於查詢計畫分析,進一步評估索引的使用效率。
總結
本文主要簡單說明了 MongoDB 多個面向的一些功能與特性,也與傳統 RDB 做了一些比較與說明。MongoDB 的發展無疑是迅速且受到關注的,彈性的開發模式、分散式架構、強大且豐富的功能吸引到一群又一群的開發者。也希望在未來的日子裡,MongoDB 能不斷進化,持續推出更多優秀的功能。
參考
- Indexes
- Read Isolation, Consistency, and Recency
- WiredTiger Storage Engine
- Tunable Consistency in MongoDB
- MongoDB 一致性模型设计与实现
